ISSN : 2349-3917
American Journal of Computer Science and Information Technology
Abstract
A Novel Approach to Vector-based Video Compression through Motion Tracking
As the age of technology progresses, the demand for video with higher resolution and bitrate increases accordingly, and as video compression algorithms approach neartheoretically perfect compression, more bandwidth is necessary to stream higher-quality video. Higher pixel resolutions do not change the fact that scaling individual frames using bilinear or bi cubic filtering naturally causes the video to lose detail and quality. In addition, as the number of pixels per frame continues to increase, so does the file size of each frame and ultimately the file size of the fully rendered video. Over time, as file size increases and required bandwidth increases, the cost of hardware systems multiplies, requiring a solution for further compression. Using core concepts of computer vision and Bezier models, this project proposes a method of converting pixel-based frames into a graphical vector format and applying motion tracking methods to compress the rendered video past current compression techniques. The algorithm uses the canny operator to break down pixel-based frames into points and then obtains Bezier curves through taking the matrix pseudo inverse. By tracking the motion of these curves through multiple frames, we group curves with similar motion into “objects” and store their motion and components, thus compressing our rendered videos: adding scalability without losing quality. Through this approach, we are able to achieve an average compression rate of 88% over industry-standard compression algorithms for ten sample H.264-encoded animation videos. Future work with such approaches could include modeling different lighting or shading with similar Bezier splines as well as bypassing pixel-based recording altogether by introducing a method to record video in a directly scalable format.
Author(s): Kanav Kalucha and Abhi Upadhyay
Abstract | Full-Text | PDF
Share This Article
Google Scholar citation report
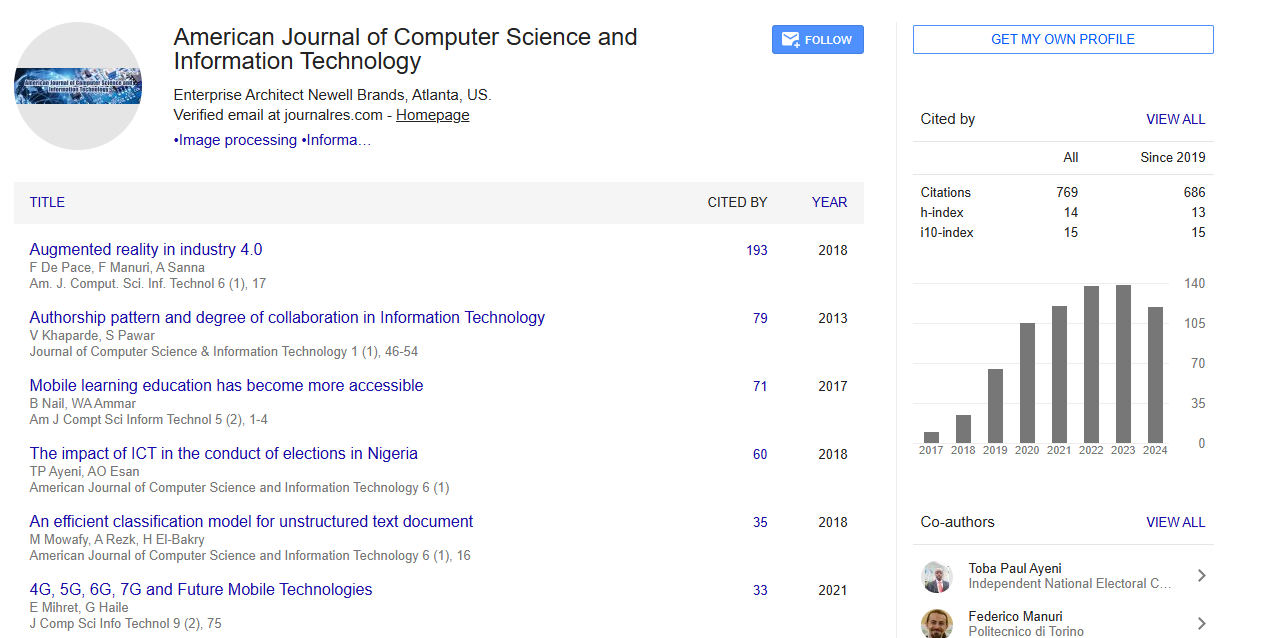
Citations : 769
Abstracted/Indexed in
- Google Scholar
- Genamics JournalSeek
- China National Knowledge Infrastructure (CNKI)
- CiteFactor
- Open Academic Journals Index (OAJI)
- Directory of Research Journal Indexing (DRJI)
- Jour Informatics
- CiteSeerx
- Journal Index.net
- Secret Search Engine Labs
Open Access Journals
- Aquaculture & Veterinary Science
- Chemistry & Chemical Sciences
- Clinical Sciences
- Engineering
- General Science
- Genetics & Molecular Biology
- Health Care & Nursing
- Immunology & Microbiology
- Materials Science
- Mathematics & Physics
- Medical Sciences
- Neurology & Psychiatry
- Oncology & Cancer Science
- Pharmaceutical Sciences