Keywords
Observational learning; Self-observation; Contextual interference; Verbal cueing; Visual cueing
Introduction
Introduce the problem
Motor skill acquisition often involves the transfer of information between an instructor and learner in an attempt to accelerate the learning process. One of the most common methods of transfer involves the use of demonstrations [1,2]. The process by which an observer adapts his or her movements as a result of watching a model is known as observational learning. A meta-analysis of the observational learning literature has shown that this process is more effective than practice alone. However, the process and the conditions by which observation of an action produces learning benefits are still unclear [3-6]. Consistent with Bandura’s conceptualization of the modeling process, researchers have shown that the use of observation improves cognitive representations of the movement, as measured by recall and recognition tests. Findings on the use of observation are also consistent with the direct perception perspective [7], whereby observers pick up relative motion information from a demonstration and use this information to produce novel or unfamiliar coordination patterns. These benefits have been shown for serial as well as continuous and discrete tasks [8]. This illustrates the universality of observation as a tool within the motor skill domain. Most researchers use others as a model. However, others believe that when you view yourself as a model, more effectively processed and used modeling technique strategies.
Self-observation is a process where people watch their own performance of a skill. In relation to self-observation one would expect observation of the self to be a better model than observation of another. While some studies have shown positive effects for the self-observation video [9,10], one study has shown it to be less effective, and one reported no differences between Self-observation and other model types. Ashford et al. suggested that skill classification could moderate observation benefits, a self-observation video was more effective than other modeling techniques for discrete skills such as a jump landing task used in basketball [11] and a volleyball serve [12] as well as continuous skills such as swimming, so other variables should be considered. Magill has shown that the effect of showing demonstration on learning is depending on skills characteristics and is most effective when the skill needs a new pattern of coordination. It seems that videos convey a lot of information in a moment and the learner does not know extract which one as a feedback. So, the coach’s mention on important points while watching the video by the learner is more helpful than when the learner watches it without any pointers [13,14]. Aiken et al. suggested that when learners are presented with information rich feedback, such as video, they request feedback after both good and poor trials [15]. The mere observation of a motor skill does not automatically lead to the learning of that task. From Bandura’s perspective, for example, attention and retention processes need to be engaged to form a cognitive representation that is later used in behavior reproduction. Neuroscientific research has also shown that the nature of instructions prior to observation modifies the neural structures employed during action observation [16,17]. Consequently, research considering the factors that can supplement the observation experience to optimize its effectiveness is important. According to Rosen et al. there is a framework in which to understand how Instructional features can accompany observation. This framework consisted of five categories that were embedded in three different levels of decision points. The first level concerned whether the instructional feature involved providing the learner with information (passive feature) versus giving the learner an activity to supplement the observation (active feature). Both passive and active categories of instructional features with observation have been manipulated in the research. In terms of the passive category, the dominant design has been to add verbal cues to the modeled information. Verbal cues are described as succinct statements, typically of just one or two words, that are used to direct a learner’s attention to relevant features of a skill or to trigger key movement pattern elements of a motor skill [18]. In the context of the use of observation, the verbal cues have been used for the former function with the logic that there is often too much information to attend to in the demonstration and the observer needs guidance to detect the relevant features in the display. Janelle et al. also added a novel cueing technique, that of visual cueing. For this, directional arrows were superimposed on the video to point at key features of interest in the soccer pass. Those participants who received the visual and verbal cueing techniques showed less error and had more appropriate form than all other groups. Thus, verbal cueing reinforced with visual highlights appears to be an effective technique to enhance the use of observation [19].
Considering the results of most studies conducted so far, the present study accepted self-observation as an effective way to learn motor skills and sought a way to heighten the effectiveness of the feedback providing method. The study literature shows that instructions such as verbal and visual cues seem necessary if a person intends to identify errors and modify their technique; therefore, this study manipulates the verbal and visual cues which were given to the person on the sidelines of watching a video [20]. To examine how the information must be classified – in general and about the entire movement or by details in different stages of the task and involved body parts – might be a contributing factor in effectiveness of selfobservation. To organize verbal and visual signs related to the modified technique, random and block methods were used.
A review of the research evidence in random and blocked feedback has shown that beginners benefit more from blocked practice in the elementary phases of learning [21]. Considering that in the elementary steps, cognitive processes are required for improving the concept of movement, high CI caused by random exercise, might be more than the interference which is required for optimal learning, which can affect the learner's performance. So beginners should experience the repeated efforts of a task in low CI, and high CI can be effective when a learner has mastered a certain level of skillfulness [22,23].
However, all these results are pertinent to the physical exercise and no study has yet examined the effect of random and blocked feedback in observational learning. These two feedbacks might have different effects on learning due to the higher cognitive involvement that happens in observational learning.
Methods
Participants
The subjects of the study were 24 female (age=19 ± 1.14) undergraduate students who voluntarily participated in this study. All of these them had good health and normal vision and were all right-footed. Also they had no prior experience with the task. They were randomly divided into three groups of blocked, random and control.
Apparatus
To collect kinematic data (graphs of angle changes of hip, knee and ankle of right-foot) eight osprey infrared cameras made by motion analysis system company were used. Initial analysis of the data was performed by the cortex software made by motion analysis company.
For further processing, data were transferred to excel 2007 software and then to Matlab [24]. The task of this examination is similar to that of Janelle and Champenoy where a Canon camcorder was used to record the performance of the skilled model and participants. Target was drawn by wide tape marking on the wall. Starting line is a square with 1.2 × 1.2 square meter (Figure 1) put at a distance of 8 meters (due to lack of space and difference in gender, researcher adjusted the distance) of target. A 14-inch widescreen Asus notebook was used for demonstrating the video to participants. The task was hitting a soccer ball toward the target with proper precision and technique. The ball was placed at the starting line. The target comprised nine 30.5 cm squares and the target center was exactly in line with the starting point. To perform an accurate pass, the size of each target square was the size of a human foot (the real life target) [25,26].
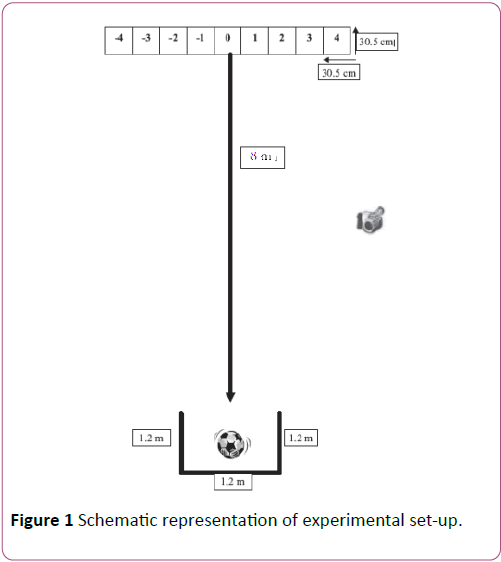
Figure 1: Schematic representation of experimental set-up.
Procedures
All efforts were recorded by camcorder for feedback and motion analysis cameras for further analysis. All participants watched the video of skilled model’s performance which was already taken of a professional football player who was modeling a right pass. In order to analyze and compare the cinematic model's movement with participants’ total of 5 reflective markers (diameter 2 cm) were used. Markers were placed on anatomical positions including the highest point of iliac crest, major trochanter and lateral epicondyle of the femur, lateral malleolus and the lateral aspect of the distal head of the fifth metatarsus [27]. Before recording, both Static and dynamic calibrations were done to determine positioning and vision range of each camera and decrease errors of cameras lenses. Then all participants performed ten efforts as a pre-test. The exercise lasted two days including six blocks of ten efforts in each day. Participants have watched the videos of their four efforts after performing ten efforts of each block. Even efforts were chosen to show to a person. So, the videos number 2, 4, 6, and 8 were shown to the person in each block. Participants in Blocked group saw their four efforts video, after completing the block. At the first and second blocks, their attention was focused on support-foot by verbal and visual cues. At the third and fourth blocks, their attention focused on indirect parts of pass (shoulder and hip) also at fifth and sixth, was guided to the movements of hit-foot. Although, participants' attention on the Random group was randomly focused on movement parts (support-foot, indirect parts of pass (shoulder and hip) and movement of hit-foot) in four views of their performance. The Control group just did the exercises after getting initial instructions. At the end last training day, one block of ten-effort acquisition (after 10 min.) and a block of ten-effort retention carried out without any observation. Quantity of learning in task’s performance was determined by comparing of the mean scores obtained from analysis of hit-foot's angles (hip, knee and ankle of right foot angle) with model's scores [28,29].
Measurement
For comparing similarity of participant's performance with model's performance, their right cinematic (three angles of hip, knee and ankle of right foot) in pre-test efforts (without any observation), acquisition and retention efforts were used [30]. Then, only related data to three angles of hip, knee and ankle of right-foot in nine efforts (including efforts number 3, 6 and 9) in each steps of pre-test, acquisition and retention were analyzed for each participant [30,31]. The range of motion was considered from separation moment of support-foot f rom the land until the most opening of hit-foot in following motion. Smooth process (to remove jerky data) and cubic join (for connecting the jump points) was performed for each angle. Numerical measure of angles in each frame were passed through the low pass forth order Butterworth 6 Hz due to cutting and separating frequencies on three equally for smooth the data as well as Excel files were extracted. And then for being comparable, all cinematic data were normalized with skilled model data (170 data) by four interpolation methods (Liner interpolation, Spline, Cubic and nearest) via Matlab software. Data were as polynomial curve and because Cubic interpolation has more mean SNR and the least error in removing jerky data (because the other three frame calculated before and after of each jerky data), this method was used for normalized data [32].
Cinematic data was recorded three-dimensional however, because the information of sagittal page shows more accurate view of skill, the cinematic parameters of this page were only discussed [33]. In order to determine the similarity of coordination pattern in participants' each angle with model pattern, bilateral correlation was used. Then all correlation grades changed to the Fisher Z (formula no.1) by Excel software and then the mean of Fisher Z grades, for participants' each three efforts in each level of test were used as participants' grade for next calculating and ANOVA analysis.
Z=1.1513 × LOG (1-r/1+r) (formula no.1)
Data and statistical analysis
Data analysis was performed by SPSS 19 statistical software. Normality of the data was determined by Kolmogorov–Smirnov test. The significant level was considered P<0.05. For comparison of three groups pre and post-test, combined factor of 3(group) × 3(day) was used. Also Bonferroni following test was used to compare pairs of groups.
Results
The results of Mixed ANOVA analysis 3 (group) × 3 (sessions) with repeated measures on the second factor indicated for coordination within the right hip the group original effect is not significant.
The main effect of training sessions in α=0/05 is not significant. The interaction of Group × the training sessions in α=0/05 is not significant (Table 1).
| Source |
Df |
Mean square |
F |
Sigma |
| main effect of group |
2 |
0.142 |
1.166 |
0.298 |
| Main effect of training sessions |
2 |
0.464 |
2.456 |
0.124 |
| Interaction effect |
4 |
0.32 |
1.714 |
0.199 |
Table 1: The analysis of variance with repeated measures of inter-limb coordination of right hip in three experimental groups.
The results of Mixed ANOVA analysis 3 (group) × 3 (sessions) with repeated measures on the second factor indicated for coordination within the right knee the group original effect is significant. The main effect of training sessions in α=0/05 is also significant [34]. The interaction of Group × the training sessions in α=0/05 is significant. To determine the differences between the experimental groups Bonferroni test was used (Table 2).
| Source |
Df |
Mean square |
F |
Sigma |
| Main effect of group |
2 |
0.314 |
4.971 |
0.017* |
| Main effect of training sessions |
2 |
0.204 |
2.83 |
0/047* |
| Interaction effect |
4 |
0.387 |
7.023 |
0.005* |
Table 2: The analysis of variance with repeated measures of inter-limb coordination of right knee in three experimental groups.
Bonferroni test results during the acquisition phase showed that, on average, there are significant differences between all groups. Study of descriptive statistics, show that the best performance is random groups and both groups have done better than the control (Table 3).
| Groups |
Random |
Blocked |
Control |
| Random |
- |
0.028 |
0.01 |
| Blocked |
0.028 |
- |
0.048 |
Table 3: Bonferroni test results on comparing coordination of knee in three experimental groups in the acquisition phase.
Bonferroni test results in the retention phase showed that there is a significant difference between blocked and control groups. But between the random-blocked and random- control groups there is no significant difference [35]. Study of descriptive statistics, show that the best performance is random group and both groups have done better than the control (Table 4).
| Groups |
Random |
Blocked |
Control |
| Random |
- |
0.034 |
0.97 |
| Blocked |
0.028 |
- |
0.021 |
Table 4: Bonferroni test results on comparing coordination of knee in three experimental groups in the retention test.
The results of Mixed ANOVA analysis 3 (group) × 3 (sessions) with repeated measures on the second factor indicated for coordination within the right ankle the group original effect is not significant. The main effect of training sessions in α=0/05 is not significant. The interaction of Group × the training sessions in α=0/05 is not significant (Table 5).
| Source |
df |
Mean square |
F |
Sigma |
| Main effect of group |
2 |
0.203 |
1.107 |
0.305 |
| Main effect of training sessions |
2 |
0.144 |
1.25 |
0.29 |
| Interaction effect |
4 |
0.143 |
1.23 |
0.306 |
Table 5: The analysis of variance with repeated measures of inter-limb coordination of right ankle in three experimental groups.
Discussion
To fully appreciate the learning process, it is crucial to consider not only practice extent but also the type and structure of practice as ways to enhance motor skill dexterity. For example, there is much evidence that perceptual forms of practice, such as observation, are sufficient to support successful retention and transfer [36-38]. Moreover, a variety of practice schedules have been associated with considerable benefits for motor learning. One that has attracted substantial attention over the past years, studied under the topic of the contextual interference effect, focuses on best practice for improving the acquisition of multiple, related motor skills [39]. Then we investigated the effect of scheduling observation on motor learning.
The overall results of this study confirm the effectiveness of the self-observation that these findings agree with studies of Christopher, Magill et al., Whiting, Tzetzis et al. and Selder and Del Rolan [38-41]. These researchers believe that people, who were observed, displayed smooth movements with less variability than their control participants. In addition, Verbal information with Visual cues, along with demonstration, increases conceptual representation and learning model performance to enhance the ability of reproducing the task.
In fact these findings Support the Bandura’s opinion which proposed that maybe it was necessary to restrict learners Attention via Oral descriptions or by emphasizing on essential features implementation model through observation (whereas conceptual display contains large amounts of extra information that is most likely unrelated to the performance of task). But the results of our study show that the effectiveness of the selfmodeling maybe affected by other factors. The group that saw the visual and verbal information along with a part of their performance video in tandem (blocked group) revealed a weaker representation of the movement [42]. This may be because the person emphasize on the negative aspects of its performance in tandem stresses according to Kimball and Cundick’s idea. These research results with Alkire and Brunse, Kimball and Cundick and Rothstein and Arnold, is aligned.
Also the results of this research can be justified in terms of contexual interference. According to the Expansion hypothesis, contextual interference caused by random practice leads to richer representation, while in the block manner encoding is weaker. Also, according to the Action plan reconstruction hypothesis, the design of a specific task operation through the efforts of the interventionist under random training program will ignore and the person is forced to utilize the more expended rebuilding process for reestablishing deed plan in next Performances, but in blocked training programs, task will not be forgotten, the action plan exists in memory and will be display in the efforts of successive [43]. Shea and Graf offered retroactive inhibition as the third main solution offered in this field. Interference occurs in learning when there is an interaction
between the new material and transfer effects of past learned behavior, memories or thoughts that have a negative influence in comprehending the new material. This theory focuses on disadvantages of blocked training instead of random practice benefits. Theory of cognitive load is in agreement with action plan reconstruction hypothesis. Random practice increases cognitive efforts in mechanisms such as increased training error and enhances learning [44]. The findings of this study are compatible with the four hypotheses.
Offering verbal and visual signs with a random way, each time focusing on one part of his or her body, increased cognitive load to identify and remember errors and will be effective reproducing movements. Thus, this study supports Magill’s theory that says blocked practicing creates a contextual dependency. This study is aligned with findings of Porter et al., Memmret et al. and Simon, who believe that the random group had a better retention of the details of the task’s movement model [45]. But the findings of this study contradict those by Del Rey et al., Hebert and Landin, Landin and Hebert, Wrisberg, Del Rey and Wrisberg.
The study results have shown that beginners benefit more from blocked practicing in the first learning stages, and the conditions of high contextual interference can be effective when the learner is somewhat skilled. Also confirming the results of studies by William Betting and Simon et al., the results of the current study show that there was no progress in the decline of hip and knee performance in the random group in the acquisition phase, but, the random group had the best performance in the retention phase. According to the results of this study on the beneficial role of feedback video in the accompanying condition randomly, it seems the practice effect would increase if the learner watched his performance video in addition to performing skills between training sessions and focus on the movement of one body part each time he/she watches the video. Therefore, the learner is involved actively in the learning process, and this leads to a more profound processing of information on the movement of any part of the body.
References
- Aiken CA, Fairbrother JT, Post PG (2012) The effects of self-controlled video feedback on the learning of the basketball set shot. Front Psychol 3: 338.
- Alkire AA, Brunse AJ (1974) Impact and possible casualty from videotape feedback in marital therapy. J Consult ClinPsychol 42: 203-210.
- Badets A, Blandin Y (2005) Observational learning: effects of bandwidth knowledge of results. J Mot Behav 37: 211-216.
- Carroll WR, Bandura A (1990) Representational guidance of action production in observational learning: a causal analysis. J Mot Behav 22: 85-97.
- Darden GF (1999) Videotape feedback for student learning and performance: A learning-stages approach. J PhysEducRecreat Dance 70:40-45.
- Del Rey P (1989) Training and contextual interference effects on memory and transfer. Res Q Exerc Sport 60: 342-347.
- Dörge HC, Anderson TB, Sørensen H, Simonsen EB (2002) Biomechanical differences in soccer kicking with the preferred and the non-preferred leg. J Sports Sci 20: 293-299.
- Dowrick PW (1991) Practical guide to using video in the behavioral sciences. John Wiley & Sons Inc.
- Dowrick PW (2012) Self modeling: Expanding the theories of learning. Psychology in the Schools 49:30-41.
- Dowrick PW, Dove C (1980) The use of self-modeling to improve the swimming performance of spina bifida children. J ApplBehav Anal 13: 51-56.
- Ford P, Hodges NJ, Williams AM (2009) An evaluation of end-point trajectory planning during skilled kicking. Motor Control 13: 1-24.
- Hayes SJ, Hodges NJ, Huys R, Williams AM (2007) End-point focus manipulations to determine what information is used during observational learning. Actapsychol 126:120-137.
- Hebert EP, Landin D, Solmon MA (1996) Practice schedule effects on the performance and learning of low-and high-skilled students: An applied study. Res Q Exerc Sport 67:52-58.
- Hodges NJ, Hayes S, Horn RR, Williams AM (2005) Changes in coordination, control and outcome as a result of extended practice on a novel motor skill. Ergonomics 48:1672-1685.
- Hodges NJ, Hayes SJ, Eaves DL, Horn RR, Williams AM, et al.(2006) End-point trajectory matching as a method for teaching kicking skills. Int J Sport Psychol 7:230-247.
- Horn RR, Williams AM, Scott MA (2002) Learning from demonstrations: the role of visual search during observational learning from video and point-light models. J Sports Sci20:253-269.
- Janelle CM, Champenoy JD, Coombes SA, Mousseau MB (2003) Mechanisms of attentional cueing during observational learning to facilitate motor skill acquisition. J Sports Sci21:825-838.
- Kimball HC, Cundick BF (1977) Emotional impact of videotape and reenacted feedback on subjects with high and low defenses. J CounsPsychol 24:377.
- Lam W, Maxwell J, Masters R (2009) Analogy versus explicit learning of a modified basketball shooting task: Performance and kinematic outcomes. J Sports Sci27:179-191.
- Landers DM (1975) Observational learning of a motor skill. J Mot Behav 7: 281-287.
- Landin D, Hebert EP (1997) A comparison of three practice schedules along the contextual interference continuum. Res Q Exerc Sport 68:357-361.
- Lee TD, Magill RA (1983) The locus of contextual interference in motor-skill acquisition. J ExpPsychol Learn MemCogn 9:730.
- Lee TD, Magill RA (1985) Can forgetting facilitate skill acquisition? AdvPsychol 27:3-22.
- Lin CHJ, Chiang MC, Knowlton BJ, Iacoboni M, Udompholkul P, et al. (2013) Interleaved practice enhances skill learning and the functional connectivity of fronto-parietal networks. Hum Brain Mapp 34:1542-1558.
- Magill RA, Anderson D (2007) Motor learning and control: Concepts and applications. McGraw-Hill New York.
- Magill RA, Hall KG (1990) A review of the contextual interference effect in motor skill acquisition. Hum MovSci 9:241-289.
- McCullagh P, Burch C, Siegel D (1990) Correct and self-modeling and the role of feedback in motor skill acquisition. Annual meeting of the North American Society for the Psychology of Sport and Physical Activity Houston, Texas.
- Memmert D, Hagemann N, Althoetmar R, Geppert S, Seiler D (2009) Conditions of practice in perceptual skill learning. Res Q Exerc Sport 80:32-43.
- Porter JM, Landin D, Hebert EP, Baum B (2007) The effects of three levels of contextual interference on performance outcomes and movement patterns in golf skills. Int J Sports Sci Coach 2:243-255.
- Post PG, Aiken CA, Laughlin DD, Fairbrother JT (2016) Self-control over combined video feedback and modeling facilitates motor learning. Hum MovSci 47:49-59.
- Rey PD, Wughalter EH, Whitehurst M (1982) The effects of contextual interference on females with varied experience in open sport skills. Res Q Exerc Sport 53:108-115.
- Rothstein AL, Arnold RK (1976) Bridging the gap: Application of research on videotape feedback and bowling. Motor skills: Theory into practice1:35-62.
- Rymal AM, Martini R, Ste-Marie DM (2010) Self-regulatory processes employed during self-modeling: A qualitative analysis. Sport Psychol 24:15.
- Schmidt RA, Young DE, Swinnen S, Shapiro DC (1989) Summary knowledge of results for skill acquisition: support for the guidance hypothesis. J ExpPsychol Learn MemCogn 15:352.
- Selder DJ, Del Rolan N (1979) Knowledge of performance, skill level and performance on the balance beam. Can J Appl Sport Sci 4: 226-229.
- Shea JB, Graf RC (1994) A model for contextual interference effects in motor learning. Cognitive Assessment: Springer pp73-87.
- Sidaway B, Hand MJ (1993) Frequency of modeling effects on the acquisition and retention of a motor skill. Res Q Exerc Sport 64: 122-126.
- Simon DA (2007) Contextual interference effects with two tasks. Percept Mot Skills 105: 177-183.
- Ste-Marie DM, Vertes K, Rymal AM, Martini R (2011)Feed forward self-modeling enhances skill acquisition in children learning trampoline skills. Front Psychol 2:155.
- Tzetzis G, Mantis K, Zachopoulou E, Kioumourtzoglou E (1999) The effect of modeling and verbal feedback on skill learning. J Hum Movement Stud 36:137-151.
- Weeks DL, Anderson LP (2000) The interaction of observational learning with overt practice: Effects on motor skill learning. ActaPsychol104:259-271.
- Wright D, Verwey W, Buchanen J, Chen J, Rhee J, et al. (2016) Consolidating behavioral and neurophysiologic findings to explain the influence of contextual interference during motor sequence learning. Psychon Bull Rev 23:1-21.
- Wrisberg CA (1991) A field test of the effect of contextual variety during skill acquisition. J Teach PhysEduc 11:21-30.
- Wulf G, Hörger M, Shea CH (1999) Benefits of Blocked Over Serial Feedback on Complex Motor Skill Learning. J Mot Behav 31: 95-103.
- Zetou E, Tzetzis G, Vernadakis N, Kioumourtzoglou E (2002) Modeling in learning two volleyball skills. Percept Mot Skills 94: 1131-1142.